inplace = True, inplace =False
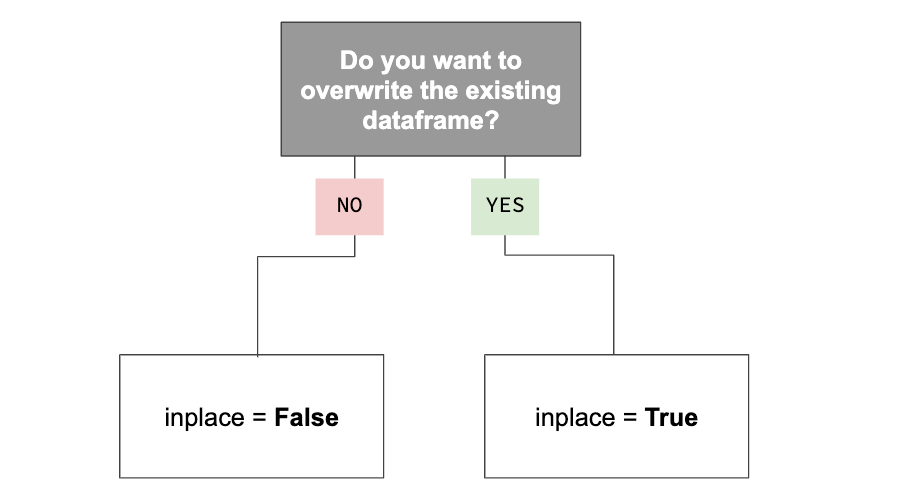
At its core, the inplace parameter helps you decide how you want to affect the underlying data of the Pandas object. Do you want to make a change to the dataframe object you are working on and overwrite what was there before? Or do you want to make a copy of the dataframe object and assign it to a different variable so you can modify that original data later? Those are the two questions you need to ask yourself. Your answers will help you determine if you need to set the inplace parameter to True or False.
Sorting an NBA Stats Dataframe
Let’s read in a dataframe with the 2018–19 Per Game Stats which we grabbed from stats.nba.com by using this handy chrome extension to easily download the data as a CSV file. We can use the read_csv() method and save it as a dataframed called df.
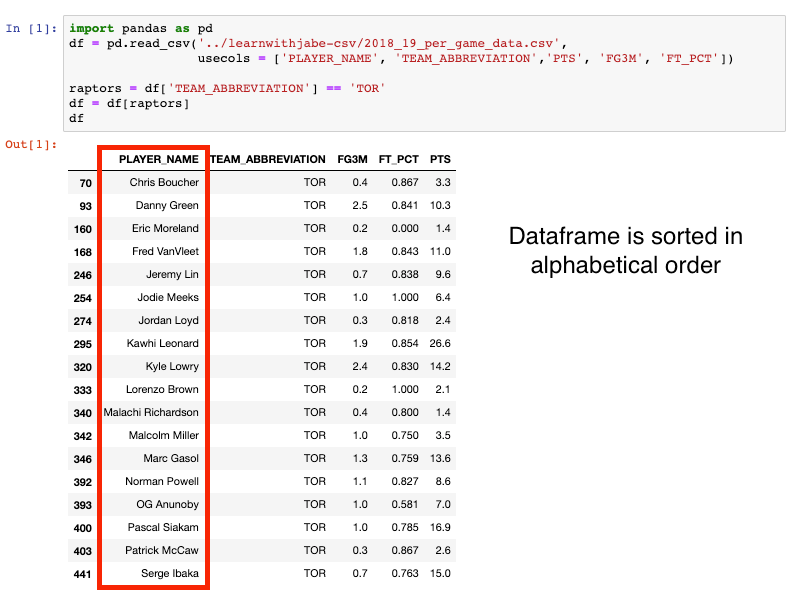
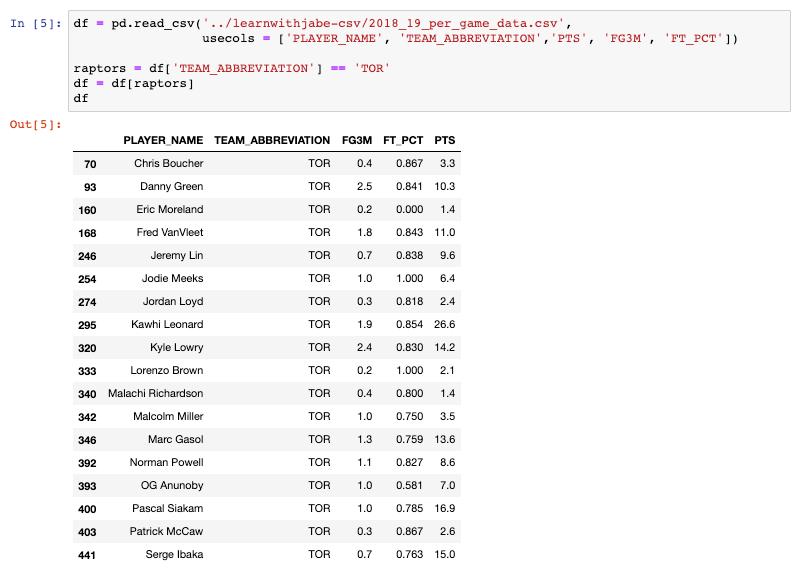
We’ll filter the dataframe to contain only the Toronto Raptors players since they are the reigning champs, and we should respect the champs. We can print the dataframe, which we’ve saved as df, by putting it as the last line of the Jupyter Notebook cell.
If you look at the output below, you’ll see the df dataframe is sorted in alphabetical order based on the player names.

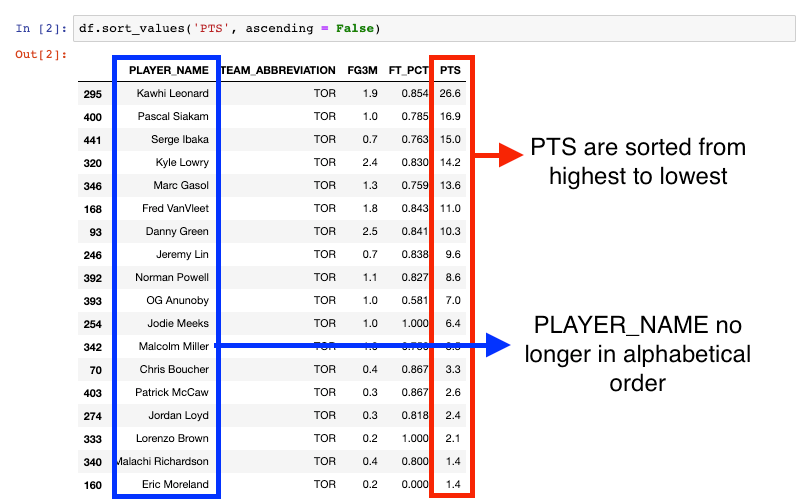
Now let’s say we wanted to sort our dataframe by the points per game column, with the highest points per game average at the top. We can use the .sort_values() method to do this.
We’ll pass it the PTS column we want to sort on and set the ascending parameter equal to False to make sure it sorts from highest to lowest. When we run this cell we get the following output:

Great! Mission accomplished. It looks like the df dataframe is sorted by the PTS column. But what happens if I print the df dataframe again in the next notebook cell? Would I still see the same ordering with Kawhi at the top?

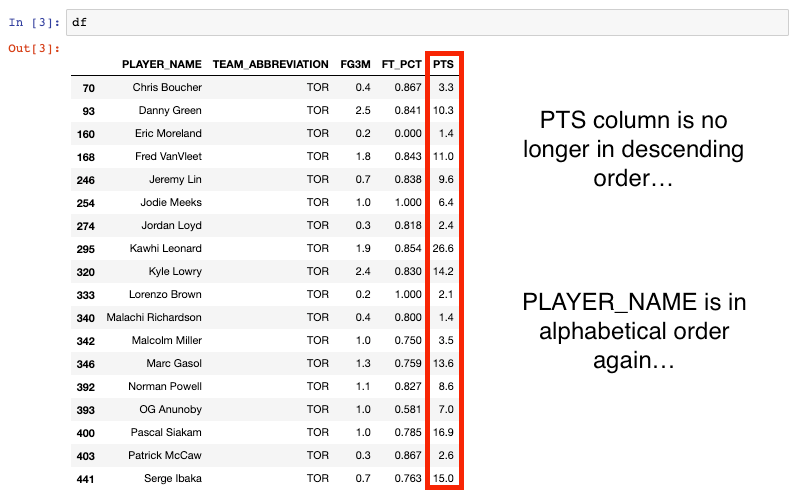
No. It reverts back to what we had before with the player names in alphabetical order…
The reason is this: whenever you modify a dataframe (aka make a change to it), the new modified dataframe doesn’t exist until you assign it to something. Until that moment, it is merely in the memory. This is often why you see the common workaround to using the inplace parameter, which is saving the dataframe back to the same dataframe variable.
Let’s sort the values again by PTS then assign it back to a df variable and print df.

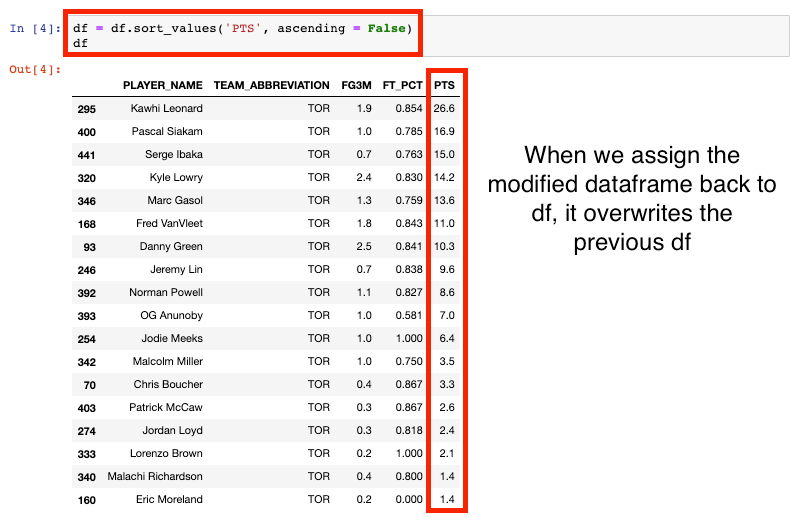
This time when we print df, it prints it in order of highest to lowest PTS. This is because we modified the data by sorting the values, then assigned it back over the original df variable. You will commonly see this practice around the web.
Sorting an NBA Stats Dataframe Using the Inplace Parameter
So where does the inplace parameter come into play? If we clear our notebook output and then rerun our original cell to get the filtered Raptors dataframe again, we can walk through the same exercise. Only this time, we will use the inplace parameter.

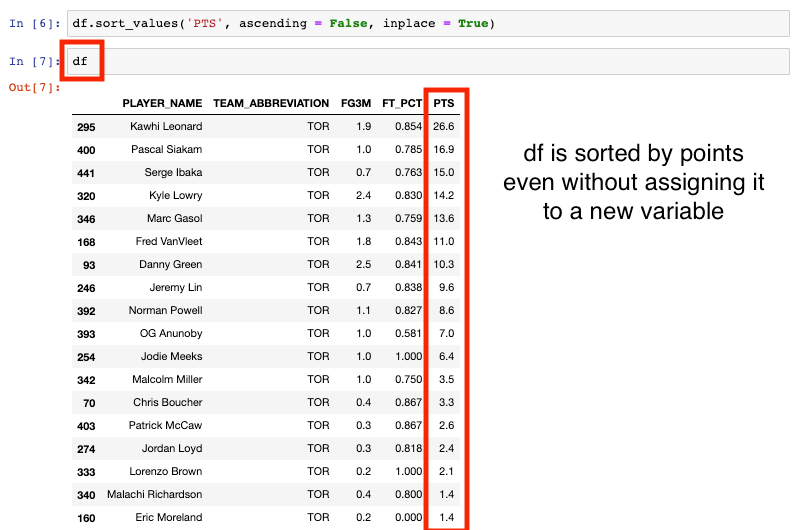
This time when we sort the values, we are going to add in the inplace parameter and set it equal to True.

Now if we print df in the next cell, we’d expect to get the unsorted Raptors dataframe again since we haven’t assigned it to any variable.
But look what happens when we print it. The dataframe is still sorted by the PTS . Ah hah! The magical inplace parameter at work!
We asked ourselves:
Do you want to make a change to the dataframe object you are working on and overwrite what was there before?
And we answered “Yes” — hence why we set the inplace parameter equal to True. Again, we told the original dataframe it was ok to update itself using the PTS in descending order change. We didn’t need to assign it to any variable. We modified the dataframe “in place.”
Setting the parameter equal to False
The flipside of this means that every time we don’t set the inplace parameter equal to True, it is set to False by default. Let’s go through the exercise one final time, making sure to call out the inplace parameter and setting it equal to False for good measure.

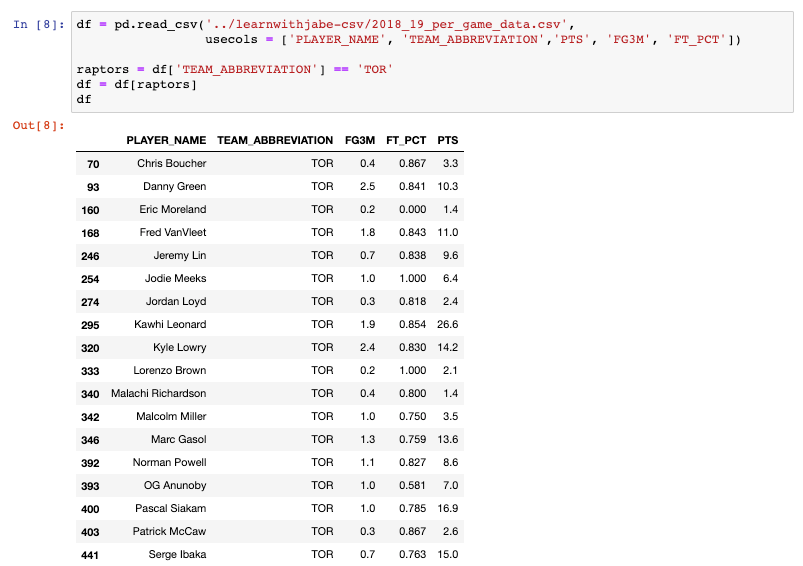
We will use the same code as our first time around, but we’ll make sure to set the inplaceparameter equal to False. If we print the dataframe, what should we expect to get?

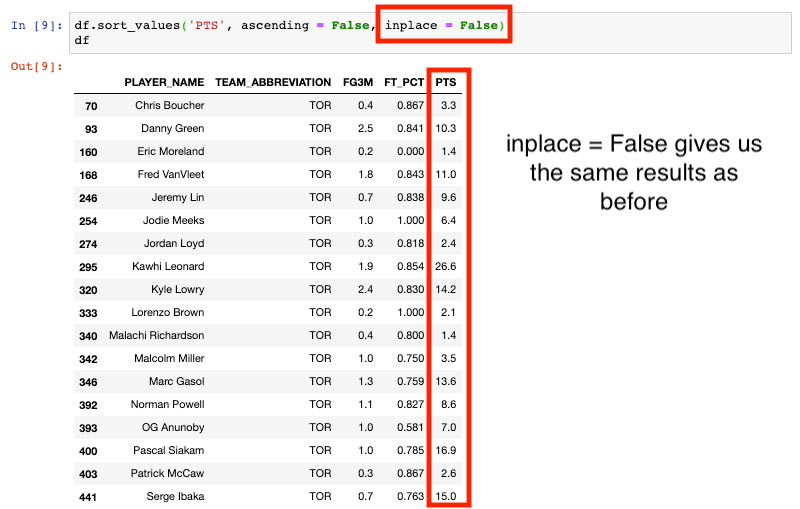
See what happens! The df is unchanged! That means this is identical to our first attempt. We just didn’t need to call out the inplace parameter since it is False by default.
Reviewing the inplace parameter one last time
To sum it up nicely for you, you can think of the True and False setting for the inplace parameter as follows:
When inplace = True, the data is modified in place, which means it will return nothing and the dataframe is now updated.
When inplace = False, which is the default, then the operation is performed and it returns a copy of the object. You then need to save it to something. That something can be a new variable or the same variable name.
No comments:
Post a Comment