A machine learning model maps a set of data inputs, known as features, to a predictor or target variable. The goal of this process is for the model to learn a pattern or mapping between these inputs and the target variable so that given new data, where the target is unknown, the model can accurately predict the target variable.
For any given data set we want to develop a model that is able to predict with the highest degree of accuracy possible. In machine learning, there are many levers that impact the performance of the model. In general, these include the following:
- The algorithm choice.
- The parameters used in the algorithm.
- The quantity and quality of the data set.
- The features used to train the model.
Often in a data set, the given set of features in their raw form do not provide enough, or the most optimal, information to train a performant model. In some instances, it may be beneficial to remove unnecessary or conflicting features and this is known as feature selection.
In other cases model performance may be improved if we transform one or more features into a different representation to provide better information to the model, this is known as feature engineering.
Feature Selection
In many situations using all the features available in a data set will not result in the most predictive model. Depending on the type of model being used, the size of the data set and various other factors, including excess features, can reduce model performance.
There are three main goals to feature selection.
- Improve the accuracy with which the model is able to predict for new data.
- Reduce computational cost.
- Produce a more interpretable model.
There are a number of reasons why you may remove certain features over others. This includes the relationships that exist between features, wether a statistical relationship to the target variable exists or is significant enough, or the value of the information contained within a feature.
Feature selection can be performed manually by analysis of the data set both pre and post-training, or through automated statistical methods.
Manual feature selection
There are a number of reasons why you may want to remove a feature from the training phase. These include:
- A feature that is highly correlated with another feature in the data set. If this is the case then both features are in essence providing the same information. Some algorithms are sensitive to correlated features.
- Features that provide little to no information. An example would be a feature where most examples have the same value.
- Features that have little to no statistical relationship with the target variable.
Features can be selected through data analysis performed either before or after training a model. Here are a couple of common techniques to manually perform feature selection.
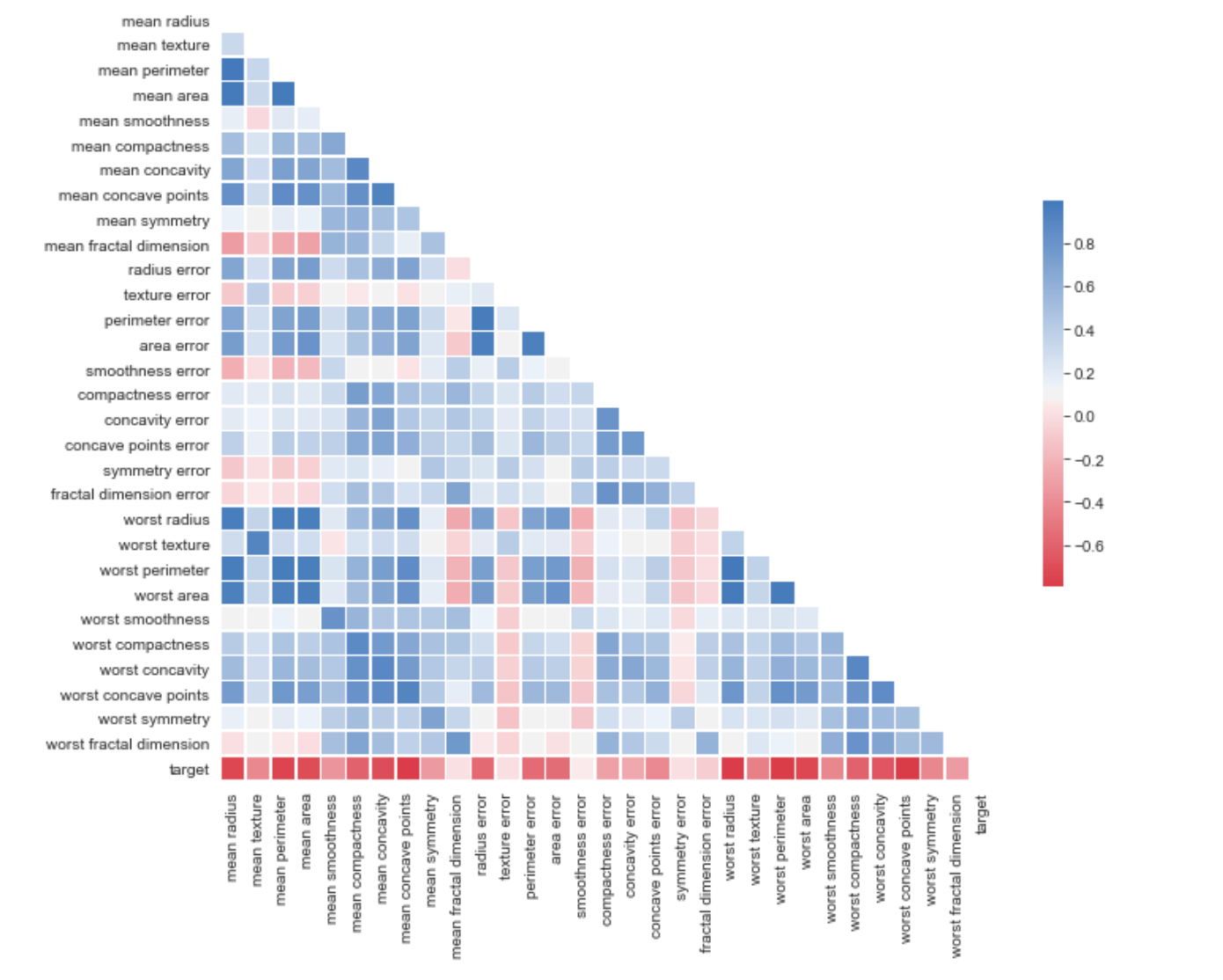
Correlation plot
One manual technique to perform feature selection is to create a visualisation which plots the correlation measure for every feature in the data set. Seaborn is a good python library to use for this. The below code produces a correlation plot for features in the breast cancer data set available from the scikit-learn API.
# library imports
import pandas as pd
from sklearn.datasets import load_breast_cancer
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import numpy as np# load the breast_cancer data set from the scikit-learn api
breast_cancer = load_breast_cancer()
data = pd.DataFrame(data=breast_cancer['data'], columns = breast_cancer['feature_names'])
data['target'] = breast_cancer['target']
data.head()# use the pands .corr() function to compute pairwise correlations for the dataframe
corr = data.corr()
# visualise the data with seaborn
mask = np.triu(np.ones_like(corr, dtype=np.bool))
sns.set_style(style = 'white')
f, ax = plt.subplots(figsize=(11, 9))
cmap = sns.diverging_palette(10, 250, as_cmap=True)
sns.heatmap(corr, mask=mask, cmap=cmap,
square=True,
linewidths=.5, cbar_kws={"shrink": .5}, ax=ax)
In the resulting visualisation, we can identify some features that are closely correlated and we may, therefore, want to remove some of these, and some features that have very low correlation with the target variable which we may also want to remove.

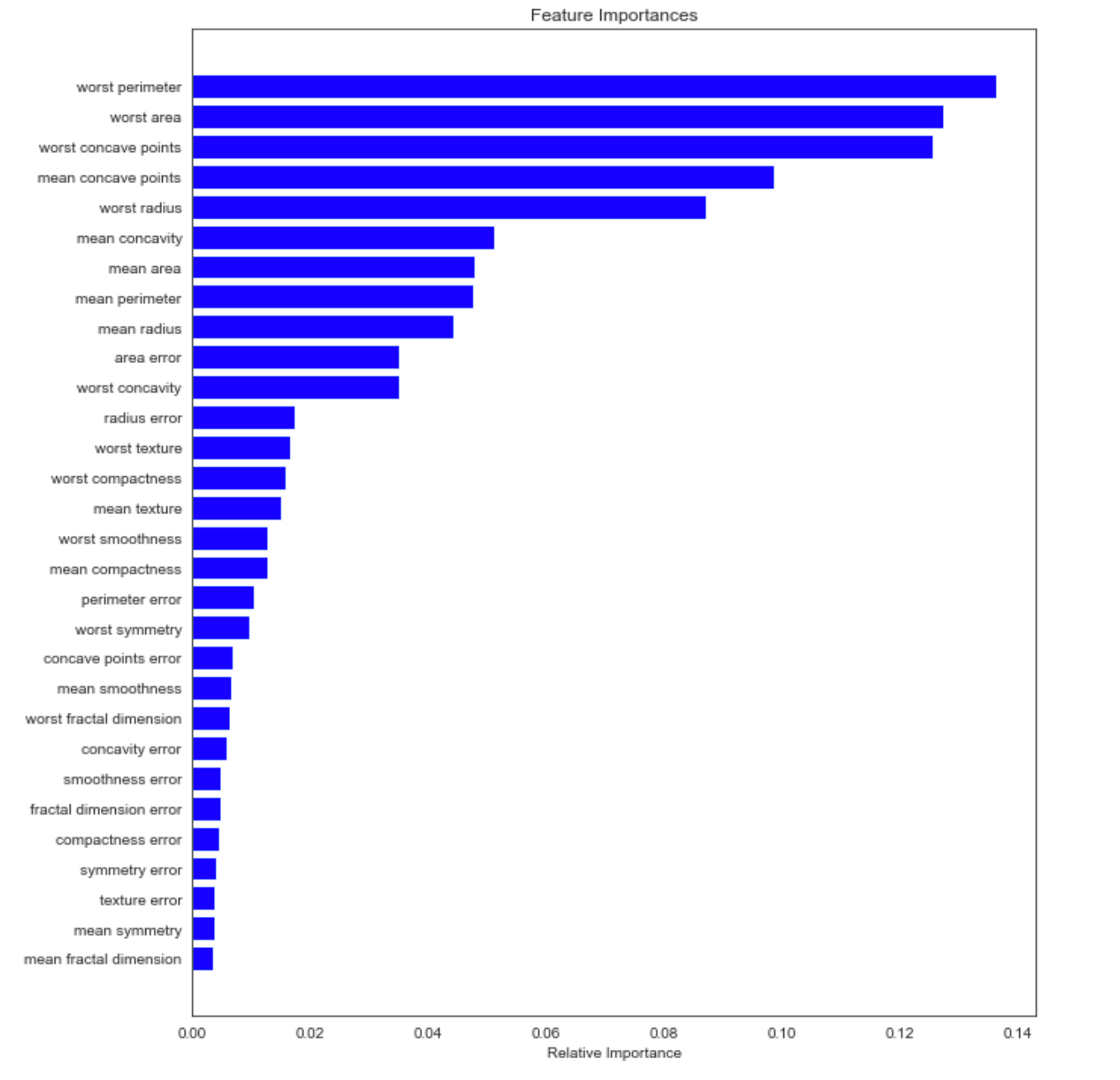
Feature importances
Once we have trained a model it is possible to apply further statistical analysis to understand the effects features have on the output of the model and determine from this which features are most useful.
There are a number of tools and techniques available to determine feature importance. Some techniques are unique to a specific algorithm, whereas others can be applied to a wide range of models and are known as model agnostic.
To illustrate feature importances I will use the built-in feature importances method for a random forest classifier in scikit-learn. The code below fits the classifier and creates a plot displaying the feature importances.
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split# Spliiting data into test and train sets
X_train, X_test, y_train, y_test = train_test_split(data.drop('target', axis=1), data['target'], test_size=0.20, random_state=0)# fitting the model
model = RandomForestClassifier(n_estimators=500, n_jobs=-1, random_state=42)
model.fit(X_train, y_train)# plotting feature importances
features = data.drop('target', axis=1).columns
importances = model.feature_importances_
indices = np.argsort(importances)plt.figure(figsize=(10,15))
plt.title('Feature Importances')
plt.barh(range(len(indices)), importances[indices], color='b', align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel('Relative Importance')
plt.show()
This gives a good indicator of those features that are having an impact on the model and those that are not. We may choose to remove some of the less important features after analysing this chart.

Automated feature selection
There are a number of mechanisms that use statistical methods to find the optimal set of features to use in a model automatically. The scikit-learn library contains a number of methods that provide a very simple implementation for many of these techniques.
Variance threshold
In statistics, variance is the squared deviation of a variable from its mean, in other words, how far are the data points spread out for a given variable?
Suppose we were building a machine learning model to detect breast cancer and the data set had a boolean variable for gender. This data set is likely to consist almost entirely of one gender and therefore nearly all data points would be 1. This variable would have extremely low variance and would be not at all useful for predicting the target variable.
This is one of the most simple approaches to feature selection. The scikit-learn library has a method called VarianceThreshold . This method takes a threshold value and when fitted to a feature set will remove any features below this threshold. The default value for the threshold is 0 and this will remove any features with zero variance, or in other words where all values are the same.
Let’s apply this default setting to the breast cancer data set we used earlier to find out if any features are eliminated.
from sklearn.feature_selection import VarianceThresholdX = data.drop('target', axis=1)
selector = VarianceThreshold()
print("Original feature shape:", X.shape)new_X = selector.fit_transform(X)
print("Transformed feature shape:", new_X.shape)
The output shows that the transformed features are the same shape so all features have at least some variance.


Univariate feature selection
Univariate feature selection applies univariate statistical tests to features and selects those which perform the best in these tests. Univariate tests are tests which involve only one dependent variable. This includes analysis of variance (ANOVA), linear regressions and t-tests of means.
Again scikit-learn provides a number of feature selection methods that apply a variety of different univariate tests to find the best features for machine learning.
We will apply one of these, known as SelectKBest to the breast cancer data set. This function selects the k best features based on a univariate statistical test. The default value of k is 10, so 10 features will be kept, and the default test is f_classif.
The f_classif test is used for categorical targets as is the case for the breast cancer data set. If the target is a continuous variable f_regression should be used. The f_classif test is based on the Analysis of Variance (ANOVA) statistical test which compares the means of a number of groups, or in our case features, and determines whether any of those means are statistically significant from one another.
The below code applies this function using the default parameters to the breast cancer data set.
from sklearn.feature_selection import SelectKBestX = data.drop('target', axis=1)
y = data['target']
selector = SelectKBest()
print("Original feature shape:", X.shape)new_X = selector.fit_transform(X, y)
print("Transformed feature shape:", new_X.shape)
The output shows that the function has reduced the features to 10. We could experiment with different values of k, training multiple models, until we find the optimum number of features.


Recursive feature elimination
This method performs model training on a gradually smaller and smaller set of features. Each time the feature importances or coefficients are calculated and the features with the lowest scores are removed. At the end of this process, the optimal set of features is known.
As this method involves repeatably training a model we need to instantiate an estimator first. This method also works best if the data is first scaled so I have added a preprocessing step that normalizes the features.
from sklearn.feature_selection import RFECV
from sklearn.svm import SVR
from sklearn import preprocessingX_normalized = preprocessing.normalize(X, norm='l2')
y = yestimator = SVR(kernel="linear")
selector = RFECV(estimator, step=1, cv=2)
selector = selector.fit(X, y)
print("Features selected", selector.support_)
print("Feature ranking", selector.ranking_)
The output below shows the features that have been selected and their ranking.


Feature engineering
Where the goal of feature selection is to reduce the dimensionality of a data set by removing unnecessary features, feature engineering is about transforming existing features and constructing new features to improve the performance of a model.
There are three main reasons why we may need to perform feature engineering to develop an optimal model.
- Features cannot be used in their raw form. This includes features such as dates and times, where a machine learning model can only make use of the information contained within them if they are transformed into a numerical representation e.g. integer representation of the day of the week.
- Features can be used in their raw form but the information contained within the feature is stronger if the data is aggregated or represented in a different way. An example here might be a feature containing the age of a person, aggregating the ages into buckets or bins may better represent the relationship to the target.
- A feature on its own does not have a strong enough statistical relationship with the target but when combined with another feature has a meaningful relationship. Let’s say we have a data set that has a number of features based on credit history for a group of customers and a target that denotes if they have defaulted on a loan. Suppose we have a loan amount and a salary value. If we combined these into a new feature called “loan to salary ratio” this may give more or better information than those features alone.
Manual feature engineering
Feature engineering can be performed through data analysis, intuition and domain knowledge. Often similar techniques to those used for manual feature selection are performed.
For example, observing how features correlate to the target and how they perform in terms of feature importance indicates which features to explore further in terms of analysis.
If we go back to the example of the loan data set, let's imagine we have an age variable which from a correlation plot appears to have some relationship to the target variable. We might find when we further analyse this relationship that those that default are skewed towards a particular age group. In this case, we might engineer a feature that picks out this age group and this may provide better information to the model.
Automated feature engineering
Manual feature engineering can be an extremely time-consuming process and requires a large amount of human intuition and domain knowledge to get right. There are tools available which have the ability to automatically synthesise a large number of new features.
The Featuretools python library is an example of a tool that can perform automated feature engineering on a data set. Let’s install this library and walk through an example of automated feature engineering on the breast cancer data set.
Featuretools can be installed via pip.
pip install featuretoolsFeaturetools is designed to work with relational data sets (tables or dataframes that can be joined together with a unique identifier). The featuretools library refers to each table as an entity.
The breast cancer data set consists of only one entity but we can still use featuretools to generate the features. However, we need to first create a new column containing a unique id. The below code uses the index of the data frame to create a new id column.
data['id'] = data.index + 1Next, we import featuretools and create the entity set.
import featuretools as ftes = ft.EntitySet(id = 'data')
es.entity_from_dataframe(entity_id = 'data', dataframe = data, index = 'id')
This gives the following output.

We can now use the library to perform feature synthesis.
feature_matrix, feature_names = ft.dfs(entityset=es,
target_entity = 'data',
max_depth = 2,
verbose = 1,
n_jobs = 3)Featuretools has created 31 new features.


We can view all the new features by running the following.
feature_matrix.columns

A machine learning model is only as good as the data that it is trained on. Therefore the steps discussed in this article of feature selection and engineering are some of the most important, and often time-consuming, parts of machine learning model development. This article has given a broad overview of the theory, tools and techniques in this field. However, this is an extremely broad area and requires a lot of practice with a variety of different data sets to really learn the art of finding the best features for machine learning.
No comments:
Post a Comment